Attention Mechanism - 1. Hard Attention
Hard Attention은 이미지의 특정 부분에 정확히 한 번만 집중하는 방식이다. Stochastic한 process라고 할 수 있다.
이 말인 즉슨, 모든 hidden state를 Decoding 과정의 input으로 사용하는 대신, hidden state를 확률 s로 샘플링하여 사용한다.
이 과정에서 어텐션 위치 변수 s_t를 사용해 어텐션할 위치를 표현한다. 이 때, Multinoulli 분포를 사용해 각 위치에 대한 확률 분포 alpha t를 설정한다.
쉽게 말하면, 어떤 위치에 집중할지는 확률적으로 결정된다는 것이다.
모델이 위치를 선택하게 되면 모델이 현재 집중하고 있는 이미지의 특정 부분을 나타내는 랜덤 변수 z_t를 정의하게 된다.
-> 이 변수 정보를 바탕으로 모델이 다음에 생성할 단어를 예측하게 된다!!
Hard Attention의 목표는 주어진 이미지에서 가장 적합한 캡션을 생성하는 것이다. 이를 위해 Log Likelihood(캡션이 나올 확률)을 최대화해야 한다.
Log Likelihood의 계산은 이미지의 특정 위치에서 얻은 z_t 값에 의존하게 된다.
이게 뭔데
Log Likleligood를 직접 계산하기가 어려워서 Log Likelihood의 Lower Bound를 사용해 근사적으로 계산하게 된다.
모든 가능한 어텐션 위치에 대해 계산하는 것이 복잡하고 비효율적이기 때문에 Lower Bound를 통해 문제를 해결한다.
Hard attention에서는 어텐션 위치가 확률적으로 결정된다고 했다. 그러나 모든 위치에 대해 계산하는 것이 매우 복잡하다. 그래서 확률적 선택으로 Log Likelihood에 대해 계산한다.

왼쪽 식은 Lower Bound, 오른쪽 식은 실제 Log Likelihood의 값이다.
Lower Bound는 Log Likelihood보다 항상 작거나 같다는 특징을 가짐을 알 수 있다.
Lower Bound는 Log Likelihood의 근사치가 되므로, 이것을 최적화하는 과정을 통해 모델은 점차적으로 정확한 캡션을 생성할 수 있게 된다. 즉, Lower Bound를 최대화하면 실제로 Log Likelihood도 증가하게 된다.
그러면 Lower Bound는 어떻게 근사해야할까?
Monte Carlo Sampling을 사용한다. Lower Bound 식에서 s는 어텐션 위치를 나타낸다. 그래서 모든 가능한 어텐션 위치 s에 대해 합산을 해야하는데 계산량이 많다는 문제가 있어서 확률적 샘플링 방법을 사용한다.
근사한 Lower Bound를 기반으로 경사 하강법과 같은 방법을 사용해 모델의 파라미터를 최적화한다. 즉, 모든 위치를 계산하지 않고도 Lower Bound를 최대화하는 방향으로 모델을 학습할 수 있게 된다.
Attention Mechanism - 2. Soft Attention
Hard Attention과 달리 확률적 선택을 하지 않고, 모든 어텐션 위치에서 가중치를 부여해 각각의 부분을 고려하는 방식이다.
즉, 모델이 입력 데이터의 모든 부분을 동시에 처리하면서도, 각 부분에 얼마나 중요한지에 대한 가중치를 다르게 주어 더 중요한 부분에 더 집중할 수 있게 된다.
각 입력 요소의 가중치 alpha i를 계산하는 과정은 softmax 함수를 통해 계산되며 다음과 같다.
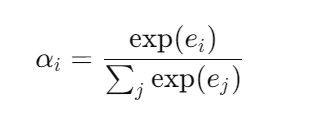
e_i는 입력 alpha i의 중요도를 나타내는 값, 즉 일종의 점수이고 이 점수는 주어진 입력과 이전의 은닉 상태를 바탕으로 계산된다.
그 다음, 입력데이터에 가중치를 적용해 최종적인 context vector z_t를 계산하게 된다.

각 a_i는 입력 데이터의 특징 벡터를 나타내며, alpha_i는 각 벡터의 가중치
Hard Attention과 비교해서 어떤 점이 좋을까?
Hard Attention과 달리 Soft Attention은 연속적인 함수라 미분 가능하기 때문에 Backpropagation을 통한 학습이 가능하다. 따라서 end-to-end 학습이 가능해 더 많은 정보를 활용해 학습할 수 있다.
end-to-end?
입력부터 출력까지 모든 과정을 하나의 모델로 연결해 학습하는 방식
Hard attention은 비연속적인 확률적 선택 과정이기 때문에 end-to-end 학습이 어렵다. 샘플링 과정이 비연속적이기 때문에 Backpropagation을 통한 미분이 어렵기 때문이다.
'Deep Learning' 카테고리의 다른 글
| [NLP] BERT 모델의 사전 학습 방법인 MLM과 NSP를 알아보자 (1) | 2024.10.31 |
|---|---|
| [NLP] Self Attention과 Multi-Head Attention을 알아보자 (0) | 2024.10.31 |
| [NLP] 멀티 모달 (Multi-Modality)과 이미지 캡셔닝 (0) | 2024.10.29 |
| [NLP] 어텐션 메커니즘 (Attention Mechanism)에 대해 알아보자 (0) | 2024.10.28 |
| [NLP] 역전파 (Backpropagation)의 개념을 알아보자 (0) | 2024.10.28 |